LAVIS (Learning and Visual Systems)
Ongoing Projects
DeepWeather
Numerische Wettermodelle berechnen den zukünftigen Zustand der Atmosphäre zu bestimmten Zeitpunkten, indem sie den auf Basis von Messungen und Sonden-Aufstiegen ermittelten Ist-Zustand durch Lösen von komplexen, extrem rechenintensiven und nichtlinearen physikalischen Gleichungssystemen für spätere Zeitpunkte prognostizieren. Während großflächige Trends hierbei mittelfristig gut prognostiziert werden können, haben die aktuellen Verfahren noch einige Schwächen für die lokale Wettervorhersage. Zum einen werden die Wetterprognosen nur in sehr groben Rastern von mehreren km berechnet. Zum anderen waren viele Messwerte bisher nicht meter- und minutengenau verfügbar. Hier setzt das vorliegende Projekt mit der Entwicklung einer meter- und minutengenauen Wettervorhersage an. Hierbei werden moderne KI-Verfahren auf Basis von hochaufgelösten lokalen Wetterdaten aus dem Internet-of-Things für die Wettervorhersage entwickelt. Der innovative Lösungsansatz besteht dabei in der dynamischen Interpolation bestehender Wettermodelle mittels Regression durch künstliche neuronale Netze und Verifikation durch die hochaufgelösten lokalen Daten.DeepWeather wird durch das Zentrale Innovationsprogramm Mittelstand (ZIM) des Bundesministeriums für Forschung, Technologie und Raumfahrt (BMFTR) gefördert.
Projektleitung:
Prof. Dr. Ulrich Schwanecke

Demo To Go
Demonstrationen sind wesentliche Elemente für den Technologieaustausch. Dazu sollen zunächst herkömmliche Demozentren eingerichtet werden, in denen ohne großen Vorbereitungsaufwand Gästen der Hochschule Forschungsresultate aus dem Anwendungsbereich Smart Home / Smart Energy / Smart Mobility sowie Technologie- und Dienstleistungsdemos aus dem Forschungsschwerpunkt "Smarte Systeme für Mensch und Technik" demonstriert werden können. In einem zweiten Schritt sollen Demos mit Methoden der Virtuellen Realität realisiert werden, um eine Ortsunabhängigkeit und in Ergänzung zu reinen Videos eine Interaktivität zu erreichen. Damit können diese Demos auf hybriden Plattformen vorgeführt werden, z.B. kann eine Demo, die besonderes Equipment am Hochschulstandort Rüsselsheim benötigt, auch am Standort Wiesbaden gezeigt werden. Andere Orte sind z.B. Messen oder Vorort-Demonstrationen bei Externen. In einem dritten Schritt sollen die Demonstrationen so erweitert werden, dass sie nicht nur von eingewiesenem Hochschulpersonal sondern auch Unternehmen und Konsumenten selber durchgeführt werden können. Methoden der Serious Games sollen
genutzt werden, um diesen ein motivierendes und unterhaltsames
Demo-Erlebnis zu vermitteln. Die Demonstrationen sollen auch in
der Lehre Verwendung finden.
durchgeführt werden können. Methoden der Serious Games sollen
genutzt werden, um diesen ein motivierendes und unterhaltsames
Demo-Erlebnis zu vermitteln. Die Demonstrationen sollen auch in
der Lehre Verwendung finden.
Projektleitung:
Prof. Dr. Ralf Dörner

Flow Lens
In unserer digital vernetzten Welt ist es wichtig und gleichzeitig zunehmend schwieriger, den Überblick über die Akteure und Vorgänge in Rechnernetzen zu bewahren. Datendiebstahl und Angriffe, Fehlkonfigurationen, Ineffizienzen und andere Anomalien müssen identifiziert, diagnostiziert und beseitigt werden um betriebliche Abläufe sicherzustellen. Dies betrifft verschiedenste Organisationen, von kritischer Infrastruktur wie z.B. Krankenhäusern über Produktionsanlagen und Unternehmen bis hin zu Behörden. Effizienz ist hier (nicht zuletzt aufgrund von Fachkräftemangel) oberstes Gebot, auch um die begrenzten IT-Budgets möglichst zielgerichtet einsetzen zu können. Flow Lens soll Netzwerkverantwortlichen neue Einblicke in die Vorgänge innerhalb ihrer Netze ermöglichen. Hierzu kategorisiert es die Akteure (oder “Knoten”) sowie die zwischen ihnen ausgetauschten Daten (oder “Flows”). Da sich die Daten, Protokolle und Knotentypen je Netzwerkumgebung und Anwendungsdomäne stark unterscheiden, soll der/die NetzwerkexpertIn interaktiv ein KI-Modell für das jeweils zu analysierende Netz anlernen können. Hierzu kategorisiert Flow Lens einfache Knoten und Datenströme vor und zeigt dem/der AnalystIn andere interessante Daten zur händischen Beurteilung auf. Sind die Vorgänge im Netz kategorisiert, wird es möglich, ungewöhnliches und verdächtiges Verhalten sowie Anomalien aufzuzeigen. Mit der Strategie, Klassifikatoren für Netzwerkdaten in der Praxis interaktiv anzulernen, betreten die Antragspartner consistec und die Hochschule RheinMain Neuland. Flow Lens geht aber noch einen Schritt weiter: Auf Grundlage der klassifizierten Flows soll es möglich sein, synthetische Netzwerkstrukturen und Flows zu erzeugen, die individuelle Kunden-Netze - datenschutzkonform - nachbilden und als Basis für weitere wissenschaftliche Arbeiten öffentlich zur Verfügung gestellt werden können. Hiermit soll Flow Lens einen Beitrag leisten, KI-gestützte Verfahren in der Netzwerkanalyse zu etablieren.
Dieses Projekt wird in Zusammenarbeit mit der Consistec GmbH durchgeführt. Es wird durch das Programm KI4KMU (FKZ: 01IS24017B) des Bundesministeriums für Forschung, Technologie und Raumfahrt (BMFTR) gefördert.
Projektleitung:
Prof. Dr. Adrian Ulges
Prof. Dr. Martin Gergeleit
MobiliAR
MobiliAR beschreitet innovative Wege, um das Marktpotenzial für Softwareunterstützung im Möbelvertrieb durch Augmented Reality (AR) und damit verbunden Computer Vision und Künstliche Intelligenz (KI) auszuschöpfen. Diese Technologien sollen es erlauben, die Möbel im Kontext des geplanten Standorts beim Kunden direkt zu erleben, aber auch neue Features im digital-gestützten Möbelvertrieb bereit zu stellen, z.B. den Möbelstandort zu vermessen, bisherige Möbel aus dem Blickfeld zu entfernen, oder Konfigurationsmöglichkeiten von Möbeln intelligent anzubieten. Neben der technischen Innovation ist eine Anwendungsinnovation Ziel von MobiliAR, wozu passende Geschäftsmodelle entwickelt und eingesetzt werden. Dies kann perspektivisch auf andere Anwendungsfälle, auch im öffentlichen Bereich, umgemünzt werden. Zur Realisierung des Vorhabens werden in MobiliAR innovative Computer Vision-basierte Features der AR-Software auf Basis des aktuellen Stands der Wissenschaft neu konzipiert, ausgearbeitet und auf technische Machbarkeit hin untersucht. Die innovativen KI-basierten Features der AR-Software werden feinspezifiziert, konzeptionell validiert und protottypisch umgesetzt. Spezifische Interaktionskonzepte für die AR-Software werden entwickelt und mit adäquaten wissenschaftlichen Methoden evaluiert. So werden völlig neue Lösungen erarbeitet und deren Praktikabilität ausgelotet.Projektleitung:
Prof. Dr. Ralf Dörner
Prof. Dr. Ulrich Schwanecke
presentXR
presentXR erlaubt, Präsentationen für die Eventbranche und für Ausstellungen mittels Augmented Reality Technologien (AR) zu kreieren und durchzuführen, die einen erhöhten Erlebniswert bieten. Durch Erzeugung einer Cross-Reality (XR), einer Verschmelzung von echten und virtuellen Räumen, fühlen sich mehrere Teilnehmende gemeinsam mit Inhalten (co-)präsent, die sowohl durch Nutzung von "Handheld- AR" mit einem Smartphone als auch durch "Head-Mounted Displays" (HMD) zugänglich sind. Es werden modulare Software-Lösungen sowie kodifiziertes Designwissen bzgl. Grafikeffekten, Interaktionsmustern und narrativen Strukturen erarbeitet. Darüber hinaus wird ein wirtschaftlicher Workflow mit Beteiligung von weniger spezialisiertem Personal angestrebt, in der Anwendung untersucht und durch Handlungsempfehlungen dokumentiert. Der Lösungsansatz von presentXR geht davon aus, dass Basistechnologien für AR-Anwendungen (wie Unity3d incl. Tracking-Plugins und Hardware-Anbindung) vorhanden sind, große Player diese aktuell weiterentwickeln, und daher auf diesen aufgebaut werden kann. Dies erfolgt sowohl aus der Richtung von Machbarkeiten, als auch wesentlich aus der Richtung eines empathischen Verständnisses (durch Design- Thinking) für End-Nutzungsbedingungen und für praktisch-/wirtschaftliche Design- und Workflow-Zwänge im Anwendungsgebiet. Teilergebnisse umfassen: Technische Demonstratoren z.B. zur Darstellung von Qualitätsabstufungen bzgl. Präsenzerleben und Co-Präsenz mehrerer Nutzender mit unterschiedlichen Endgeräten in einer zeitbasierten AR-Präsentation; die Spezifikation eines Content-Formats für die dynamische Ablaufsteuerung und für die Unterstützung des narrativen Authoring; einen Baukastensatz mit weiter verwendbaren Software-"Nuggets", die Grafik- und Content-Patterns als Code mit Anwendungswissen zur Verfügung stellen; sowie einen integrierten und evaluierten "goldenen Demonstrator" für eine praktische AR-Fallstudie aus dem Bereich der Event- und Ausstellungskonzeption.
Dieses Projekt wird in Zusammenarbeit mit der satis&fy AG durchgeführt. Es wird durch das Programm "Forschung an Fachhochschulen" (FKZ: 13FH181PX8) des Bundesministeriums für Forschung, Technologie und Raumfahrt (BMFTR) gefördert.
Projektleitung:
Prof. Dr. Ralf Dörner
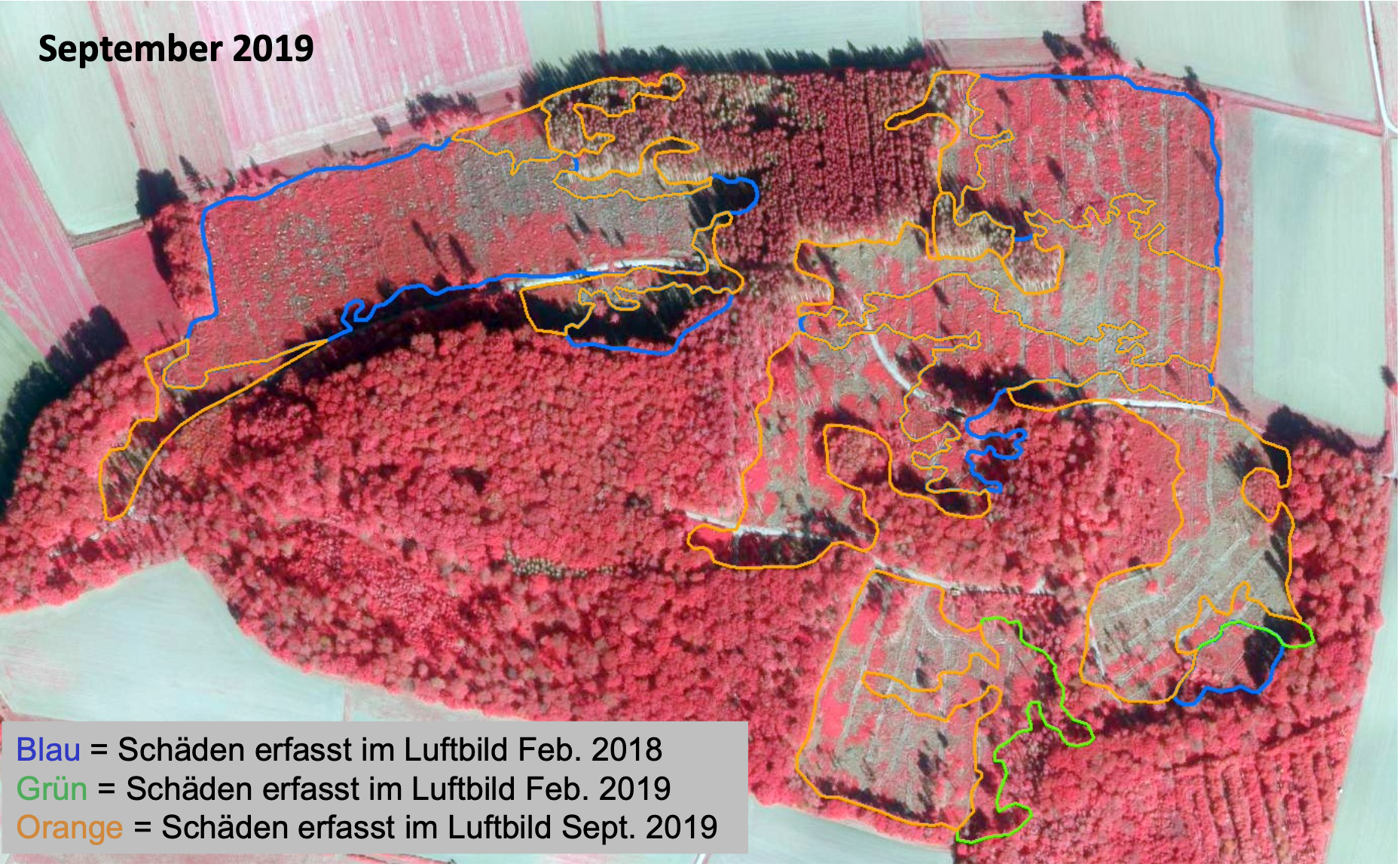
SENSURE Wald
Im Rahmen Vorhabens SENSURE Wald werden für Sentinel-2-Satellitendaten, basierend auf Künstlicher Intelligenz (KI), Modelle entwickelt, welche die räumliche Auflösung der Sentinel-2- Daten verbessern und eine hochgenaue Lokalisation auch kleiner Schadflächen ermöglichen („super-resolution“-Verfahren). Weiterhin werden Verfahren entwickelt, die auf Methoden aus dem Bereich des maschinellen Lernens, insbesondere der KI, gründen und den Datenbedarf zur Schaderfassung auf einen einzigen Aufnahmezeitpunkt reduzieren. Sowohl für Sentinel-2- als auch für Luftbilddaten werden vortrainierte Modelle entwickelt, die eine automatisierte und effiziente Erfassung von Schadflächen mit hoher Genauigkeit und Aktualität ohne die bisher nötige und aufwendige manuelle Zuarbeit erlauben.Projektleitung:
Prof. Dr. Ulrich Schwanecke
SLIMDOC
Trotz zunehmender Digitalisierung werden Dokumente wie Rechnungen, Geschäftsberichte, Beschwerden, Formulare und Verträge weiterhin häufig genutzt. SLIMDOC adressiert neuartige KI-Modelle für automatisiertes Dokumentverstehen, also für die korrekte Auswertung solcher unstrukturierten Dokumente, noch immer ein Kernproblem effizienter Geschäftsprozesse. Besonders herausfordernd ist es, multimodale Dokumente zu verstehen: Diese besitzen nicht nur komplexe textuelle Inhalte oder Layouts, sondern enthalten neben Text auch Bilder wie Grafiken oder Fotos. SLIMDOC möchte KI-Modelle entwickeln, die solche Dokumente zuverlässig analysieren, und zwar leichtgewichtig: Einerseits, indem teures Datensammeln und händische Annotation vermieden werden, und andererseits durch kompaktere Modellarchitekturen, die eine zeit- und energiesparendere Inferenz gestatten. Hierzu werden drei Forschungsthemen adressiert: (1) Distillation: SLIMDOC möchte aus Large Language Models, die für ihre erstaunlichen Problemlösefähigkeiten bekanntermaßen Milliarden von Parametern nutzen, kleinere Modelle extrahieren, die auf den jeweiligen Extraktions-Task spezialisiert sind. (2) SLIMDOC möchte Dokumente ähnlich zu denen eines Use Cases datenschutzkonform synthetisieren, so dass KI-Experten wertvolle Daten für Off-Premise-Training und Optimierung gewinnen. (3) SLIMDOC möchte Text- und Bildinformation (welche bislang eher als unterstützendes Signal dient) auf neuartige Weise kombiniert betrachten, so dass sich auch spezialisierte multimodale Informationsextraktions-Tasks lösen lassen.
Dieses Projekt wird in Zusammenarbeit mit der R+V Versicherung AG, der Insiders Technologies GmbH und der Doxis GmbH durchgeführt. Es wird durch das Bundesministerium für Forschung, Technologie und Raumfahrt (BMFTR) gefördert (FKZ: 13HAW15PX4).
Projektleitung:
Prof. Dr. Adrian Ulges

VaStNet
Digitale Wertströme stellen Modelle von Produktionsprozessen dar und umfassen oft mehrere hundert Knoten mit Annotationen (wie den erzeugten Produkten und Laufzeiten). Die korrekte Erstellung eines Wertstroms ähnelt somit der Erstellung einer Software durch einen Programmierer: Häufig unterlaufen Fehler, die anhand des Verhaltens des Wertstroms schwer zu lokalisieren und beheben sind. So bleibt digitale Wertstrommodellierung bis heute überwiegend Simulationsspezialisten vorbehalten. Genau hier setzt das Vorhaben VaStNet an: Ziel ist es, Nutzer KI-gestützt bei der Modellierung korrekter Wertströme zu unterstützen. Hierzu sollen Lernverfahren entstehen, die den Wertstromexperten als digitaler Assistent unterstützen. VaStNet baut auf erfolgreichen Vorarbeiten der Hochschule RheinMain und der SimPlan AG auf, in denen weltweit erstmalig KI-Methoden zur interaktiven Reparatur von Wertströmen eingesetzt wurden. Diese Arbeiten werden nun auf drei Ebenen mit neuen Innovationen erweitert: Der Adaptionsebene (indem die KI auf die spezifischen Wertströme eines Kunden anpassbar wird), der Modellebene (indem ein Deep Learning - Modell Verwendung findet), sowie der Simulationsebene (indem das Modell die Simulationsergebnisse des Wertstroms für seine Empfehlungen berücksichtigt).
Dieses Projekt wird in Zusammenarbeit mit der SimPlan AG durchgeführt. Es wird durch das Programm KI4KMU (FKZ: 01IS24015C) des Bundesministeriums für Forschung, Technologie und Raumfahrt (BMFTR) gefördert.
Projektleitung:
Prof. Dr. Dirk Krechel
Prof. Dr. Adrian Ulges

VR-AR-Med2
Virtuelle Realität (VR) und Augmentierte Realität (AR) sind Technologien, die aufgrund ihrer Verfügbarkeit im Massenmarkt in den Blickpunkt zahlreicher Innovationen gelangt sind. Es gilt deren Potenzial für konkrete Anwendungen auszuschöpfen und den Mehrwert ihres Einsatzes hierbei nachzuweisen. Im Projekt wird die konkrete Anwendung der medizinischen Weiter- und Fortbildung (CME – Continuing Medical Education) betrachtet. Hier sehen Unternehmen wie der Antragssteller, die health&media GmbH (HM), hohe Nutzenpotenziale durch den Einsatz von VR/AR, die sich in effizienterem Lernen, höherer Motivation, Vermittlung von Zusatzqualifikationen sowie höherer Attraktivität des Lehrmaterials manifestieren. Die Gruppe LAVIS der Hochschule RheinMain (HSRM) unter Dr. Ralf Dörner bringt hier innovative Ansätze wie das Konzept der VR/AR-Nuggets (ein Pattern-basierter Ansatz, der in kombinierbaren, ständig lauffähigen Anwendungen umgesetzt wird), eine KI-basierte VR/AR-Guidance als auch ein punktuelles Einsatzkonzept von VR/AR im Kurs ein.Dieses Projekt (HA-Projekt-Nr.:690/19-10) wird im Rahmen der Innovationsförderung Hessen aus Mitteln der LOEWE - Landesökonomischer Exzellenz, Förderlinie 3: KMU-Verbundvorhaben gefördert.